Finetuning Visual
Autoregressive Models
for Controllable
Image Generation
The first framework to integrate spatial control into a scale-wise autoregressive text-to-image model. Two novel architectures, six control modalities, and a unified model that routes them all with a single checkpoint.




Motivation
The Empty Cell
Spatial control existed for diffusion models. For autoregressive T2I models, one specific combination remained unexplored.
The research landscape for controllable autoregressive generation can be mapped along two dimensions: the generation task (text-to-image vs class-to-image) and the prediction paradigm (next-token vs next-scale).
When examined collectively, prior work — ControlAR, CAR, ControlVAR, and SCALAR — leaves exactly one cell vacant: text-to-image with next-scale prediction.
C2I models avoid dual conditioning (one class label, not open-ended text). ControlAR avoids hierarchical alignment (flat token stream, not 10 resolution scales). Our framework confronts both simultaneously.
| Next-Token | Next-Scale | |
|---|---|---|
| Text-to-Image | ControlAR | ★ This work Switti-Control |
| Class-to-Image | — | CAR · ControlVAR SCALAR |
Methodology
Two Architectures,
One Philosophy
Both approaches keep the SWITTI backbone frozen and use zero-initialized projections to start training from pretrained behavior.
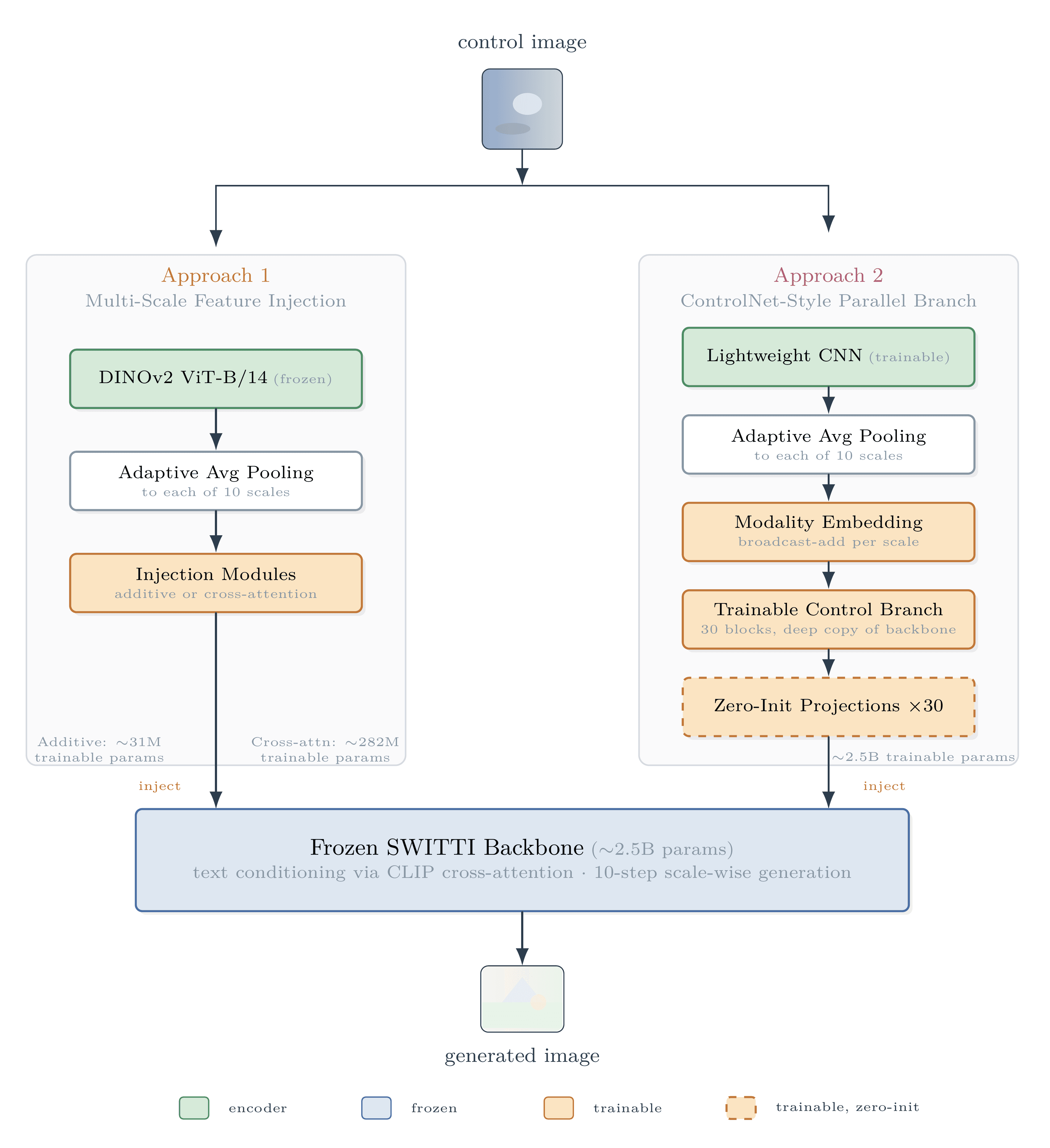
Encoder Injection
LightweightA frozen DINOv2 ViT-B/14 encoder extracts rich features from the control image. These features are pooled to match each of SWITTI's 10 generation scales, then injected after self-attention and before text cross-attention.
Parallel Control Branch
Full-scaleA full copy of the SWITTI backbone runs in parallel, processing the control image and injecting control features via zero-initialized linear layers — the same design principle that made ControlNet work, reimagined for next-scale autoregressive generation.
Results
Qualitative Results
Parallel Control Branch outputs across three modalities. The model follows the structural layout of the control map while respecting the text prompt.








Key Results
By the Numbers
Unified Control
One Model.
Six Modalities.
A single checkpoint with a learned modality embedding routes six structurally distinct control signals without interference. Within 10–15% of per-modality specialists.







Same source scene, six different structural control signals — all from one unified model.
Design Principle
Pretrained Quality
Preserved
The frozen backbone strategy ensures the base model's text-to-image behavior is fully preserved. Without a control signal, all variants generate normally.
“Professional motorcycle racer in extreme lean on a race course.”

+ normals

·

Pure T2I
no control
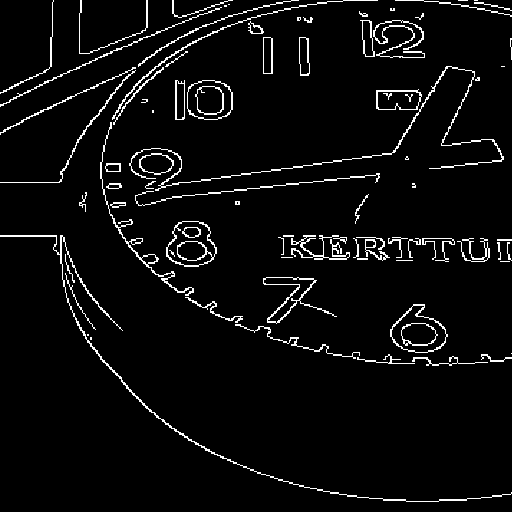
Control Map
surface normals
Controlled
same model